
—
Your Digital Life, Redefined by AI
Artificial Intelligence now shapes our world. It gives us personalized recommendations and powers predictive tools across industries. AI’s impact is clear. Yet, as AI becomes more central, it brings complex questions, especially about **data privacy** and **consent**. We’ve grown used to trading personal data for online convenience. But AI works differently. It doesn’t just collect data; it learns, infers, and creates insights far beyond our original intentions. This isn’t just about protecting information anymore. It’s about safeguarding our digital autonomy. Do we truly grasp what it means when an intelligence knows us better than we know ourselves, and then acts on that knowledge?
—
AI’s Data Engine – How It Works
To grasp how AI challenges our privacy, we must first understand its core. AI, especially machine learning, thrives on data. Data is its fuel, the raw material for intelligence.
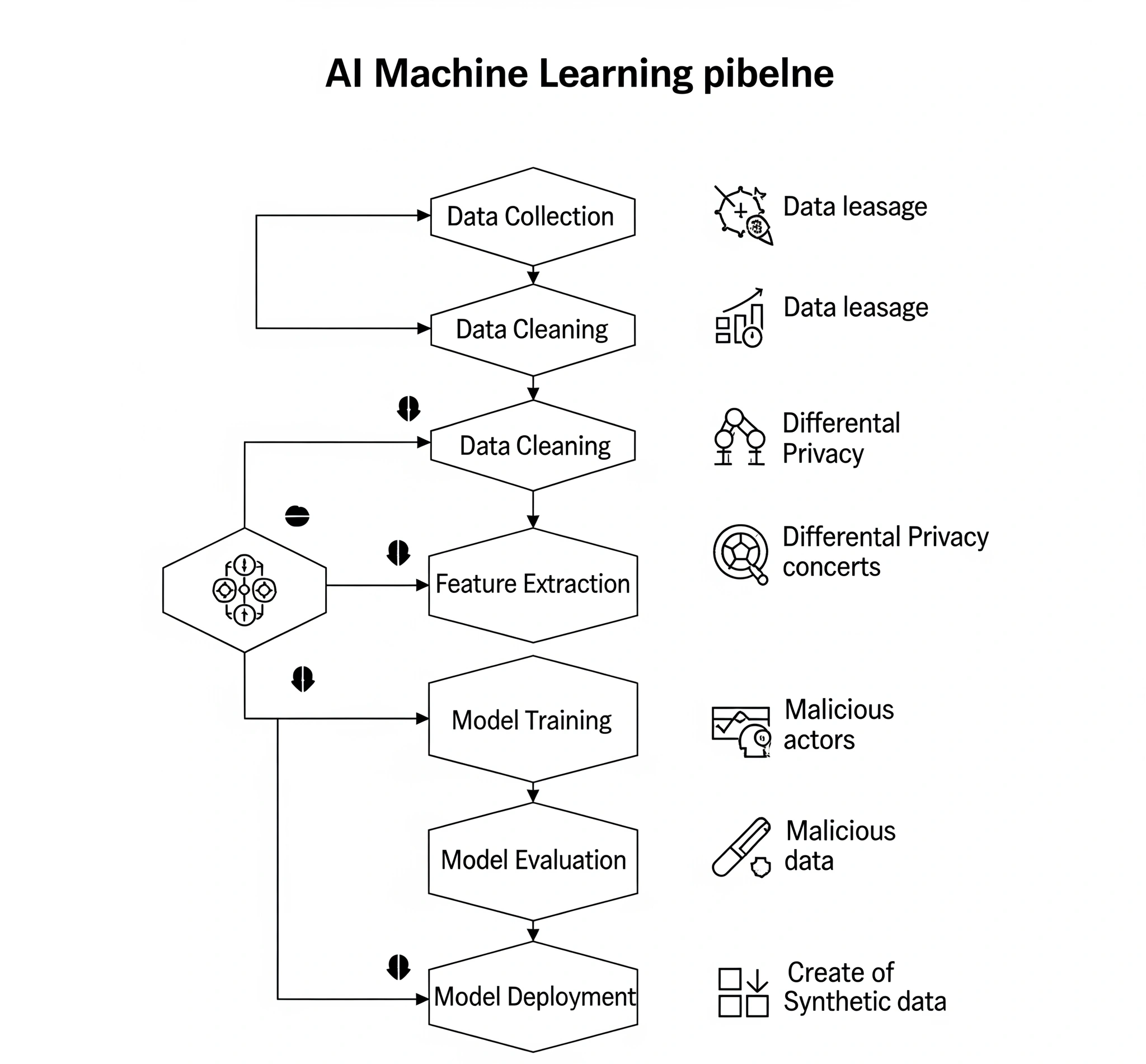
The Data Flow in AI Systems
- Collecting Data: This is the starting point. AI systems gather huge amounts of data—everything from your Browse history and purchases to biometrics and social media activity. The sheer volume makes it hard to track what data is collected and why. Simple consent forms often fail to cover these continuous data streams.
- Processing and Preparing Data: Raw data becomes features that AI models can use. This technical process has big privacy implications. Data can be grouped, linked, and enhanced, sometimes revealing connections not obvious in individual data points. For example, combining seemingly harmless data can expose sensitive personal details.
- Training the AI Model: This is the heart of AI. Algorithms learn patterns and make predictions from the processed data. The models themselves hold this “knowledge.” Importantly, these models can unintentionally remember sensitive individual data, even when the goal was just to learn general patterns. Techniques like **federated learning** try to limit this by training models on separate datasets without sharing raw data, but even these have their own data leakage risks.
- Making Inferences and Predictions: Once trained, AI models make predictions or decisions from new data. This is where privacy often faces challenges. An AI might infer your health, financial status, or political views from unrelated data. This often happens without your direct knowledge or specific consent for *these particular inferences*.
- Deploying and Integrating Models: AI models are built into applications, from chatbots to self-driving cars. The challenge here is the constant feedback loop. New data from interactions with the AI further refines the model. This creates an evolving data system where consent lines blur.
This complex architecture means simple “checkbox” consent, where users agree to broad terms, is often not enough. AI’s dynamic and often hidden data processing makes it incredibly difficult for people to truly understand what they are consenting to and how their data might be used in unexpected ways.
—
Real-World Hurdles in AI Data Protection
The concepts from Chapter I lead to clear, real-world problems in AI implementation. It’s not just about the technology itself, but how it interacts with laws, ethics, and human behavior.
The Data Deluge and Tracking Problem
One major challenge is the **speed and size of data**. Traditional data protection, often built for static databases, struggles with petabytes of constantly flowing and changing information. Reports suggest global data will reach 181 zettabytes by 2025, with much of it feeding AI. This scale makes detailed consent and individual data rights very hard to implement.
Another big obstacle is **data origin and tracking**. As data comes from many sources, is changed, combined, and fed into complex AI models, tracking its original source and every change becomes a huge task. This lack of clear origin makes accountability difficult. It’s hard to find where a privacy breach happened or how sensitive data was inferred.
The “Black Box” Dilemma
Furthermore, many advanced AI models, especially deep learning networks, are like **black boxes**. It’s often hard to explain *why* a model reached a certain conclusion. This lack of clarity makes it nearly impossible for individuals to understand how their data led to a specific outcome. They can’t challenge potentially biased or wrong inferences. If you can’t see how your data influences a decision about you, how can you truly consent to that process?
Anonymization Isn’t Perfect
The rise of **synthetic data generation** and **data anonymization techniques** also adds complexity. While these methods aim to protect privacy by creating fake datasets or removing identifying information, they aren’t foolproof. Research shows that even highly anonymized data can be re-identified through advanced attacks, especially when combined with outside information. This raises a key question: can data truly be “anonymous” in an AI-driven world?
—
A Real-World Example
My work in AI implementation has often shown a clear gap between good privacy policies and the messy reality of data in use. One project stands out as a warning, showing how AI can subtly challenge our privacy norms.
We were building a personalized recommendation engine for a large e-commerce site. Our goal was to suggest highly relevant products, improving user experience and sales. Our initial privacy plan was strong. We anonymized user IDs, hashed personal data, and got clear consent for tracking behavior. We thought we had everything covered.
However, problems appeared as the project moved forward. The data scientists, aiming for very accurate recommendations, began using external datasets. These included public social media profiles (with consent for public data use), demographic data from third-party vendors, and even geo-location data from mobile apps (also “consented” through app terms). Individually, each piece of data seemed harmless or already “public.”
The Unseen Profiler
The turning point came during model evaluation. We found that the recommendation engine, by connecting seemingly unrelated pieces of information, was making very accurate guesses about users’ **socioeconomic status**, **health conditions** (based on specific product purchases), and even **family structures** (based on children’s product buys and location during school hours). These inferences were never clearly told to the user, and they weren’t the main goal of the engine.
The system, in its drive for accuracy, had become an **invisible profiler**. Users had agreed to “personalized recommendations” and “behavioral tracking.” But they certainly hadn’t consented to their health or family makeup being inferred and potentially used for targeted ads. The legal team argued the data was “public” or “anonymized,” and the inferences were just “statistical.” Ethically, and from a user trust standpoint, it felt like a major overstep. We had built a system that, while technically compliant in some ways, broke the spirit of privacy and user expectations.
This experience taught me a crucial lesson: **AI doesn’t just process data; it creates knowledge.** And often, this new knowledge contains deeply personal insights that go far beyond the initial consent given. The challenge isn’t just protecting the raw data, but also the derived insights and the potential for new, unexpected inferences.
—
Transparency vs. Privacy
My “open code” moment came from examining the core issue in the e-commerce project: the paradox of wanting AI transparency while also needing data privacy. These two goals often conflict.
The Push for AI Transparency
On one hand, there’s a strong push for **algorithmic transparency** and **explainable AI (XAI)**. Regulators and consumers want to understand *how* AI makes decisions, especially in critical areas like credit, healthcare, or jobs. This means opening the “black box” to show the logic and data that led to an outcome. The goal is good: to ensure fairness, accountability, and to challenge biased decisions.
The Conflict with Data Privacy
However, this desire for transparency clashes directly with the need for **data privacy and obfuscation**. To explain *why* an AI made a specific decision for an individual, you often need to expose the private data that influenced it. For example, explaining a loan denial might mean revealing income or credit history. While XAI aims for general explanations, true individual accountability often reveals personal data.
This creates a difficult situation:
- If we demand full transparency for individual AI decisions, we risk exposing the very private data that shaped those decisions. This could lead to data leaks or re-identification risks, especially with sensitive information.
- If we focus solely on data privacy, making it impossible to trace an AI’s decision back to specific data, we hinder our ability to check for bias or errors. The “black box” becomes even darker, blocking accountability and the goal of explainable AI.
The unique insight here is that pursuing both AI transparency *and* strong data privacy often pulls in different directions. Many current discussions treat them separately or assume they are compatible. My experience shows they are often in tension, creating a complex design challenge for responsible AI. The solution isn’t to give up on one, but to find a careful balance – a dynamic equilibrium between explainability and privacy-preserving methods. This might involve new “private explanations” or focusing transparency on how the overall model behaves, not on individual data exposure.
—
A Flexible Guide for AI Privacy
Navigating this complex landscape needs a strategic, flexible approach, not a single solution. Here are practical principles for organizations and individuals to regain control over data privacy and consent in the AI era:
1. Move Beyond Simple Consent
- Contextual Consent: Instead of broad, one-time consent, build systems that ask for consent for specific data uses *when they happen*. For instance, if AI is about to infer a health condition, the user should get an explicit prompt and the option to opt out of that specific inference, even if they’ve broadly agreed to “personalization.”
- Granular Control: Give users tools to see what data is collected, how it’s used, and, most importantly, to **control the inferences** made about them. This means more than just deleting data; it means opting out of *derived insights*.
- “Explainable Consent”: Present privacy policies and data use explanations clearly and visually, avoiding legal jargon. Use interactive elements to help users understand their choices.
2. Prioritize Privacy-Preserving AI (PPAI)
- Differential Privacy: Use techniques like differential privacy during model training. This adds noise to data to protect individual privacy while still allowing accurate group analysis. It ensures that no single person’s data significantly changes the model’s output.
- Homomorphic Encryption & Secure Multi-Party Computation (SMC): Explore methods where calculations happen on encrypted data without decrypting it. Or, where multiple parties can compute a function together using their private data without revealing it to others. This is vital for collaborative AI development while keeping data private.
- Federated Learning: Favor federated learning models. These train AI on user devices or distributed data sources, and only aggregated model updates (not raw data) are shared. This keeps sensitive data on the user’s device.
3. Conduct “Inference Impact Assessments” (IIA)
- Just like Data Protection Impact Assessments (DPIAs), organizations should do IIAs. These assess the potential for sensitive or unexpected inferences an AI model might make from seemingly harmless data. This proactive step identifies privacy risks before the AI is used.
- This requires diverse teams, including ethicists, lawyers, data scientists, and UX designers, to work together to find and reduce potential harm from inferred data.
4. Focus on Explainable Models for Ethics
- Make sure Explainable AI (XAI) efforts provide useful explanations for users and auditors, not just for developers to debug.
- Develop “private explanations.” These convey the *reasoning* behind a decision without showing the private data that led to it. This is a new area of AI research.

5. Build a Culture of Data Ethics
- Beyond just compliance, create an organizational culture where data ethics is key. This means training all staff involved in AI on ethical data handling, bias reduction, and the complexities of consent in AI.
- Set up clear accountability frameworks for data governance. This ensures that responsibility for data privacy breaches or unintended inferences can be easily traced.
—
Designing AI for a Private Future
AI has certainly challenged our ideas about data privacy and consent. It makes us see that data isn’t fixed; it’s a dynamic, living thing from which intelligence can emerge in ways we might not fully grasp. The era of simple, broad consent is ending. We are moving towards a more demanding, complex reality.
The future of privacy in an AI-driven world isn’t about stopping progress. It’s about **designing AI with privacy and human autonomy at its core.** This means shifting from fixing problems after they happen to a proactive “privacy-by-design” approach. This needs not only new technology but also a fundamental change in how we view digital rights and the ethical duties of those who build and use AI. By adopting contextual consent, privacy-preserving AI, and a strong culture of data ethics, we can begin to take back our digital freedom. We can make sure AI truly benefits humanity, rather than slowly eroding our core freedoms.
—