
—
Dissecting the Core Architecture
We live in an age where Artificial Intelligence is no longer a futuristic fantasy but an integral part of our daily lives. From recommending our next binge-watch to powering medical diagnoses, AI’s influence is ubiquitous. Yet, beneath the veneer of seamless efficiency and groundbreaking innovation, a disquieting question persists: Can we truly trust AI? As a digital architect who has spent years building and deploying AI systems, I’ve witnessed firsthand the immense promise and the profound pitfalls. The challenge isn’t just about making AI work; it’s about making AI work ethically and fairly. This isn’t a theoretical debate for academics; it’s a pressing concern for every business, every developer, and every individual impacted by these increasingly powerful algorithms. Truly, the stakes are too high to ignore the hidden biases and ethical dilemmas lurking within the code.
—
At its heart, AI, particularly Machine Learning (ML), learns from data. This learning process, while powerful, is also its greatest vulnerability when it comes to ethics and bias. Think of an ML model as a student. If you feed that student biased textbooks, they will inevitably form biased conclusions.
The core architecture of most modern AI systems relies on neural networks and various ML algorithms like decision trees, support vector machines, and deep learning models. These algorithms are designed to identify patterns, make predictions, and classify data.
How Machine Learning Works
Here’s a simplified breakdown of the typical workflow:
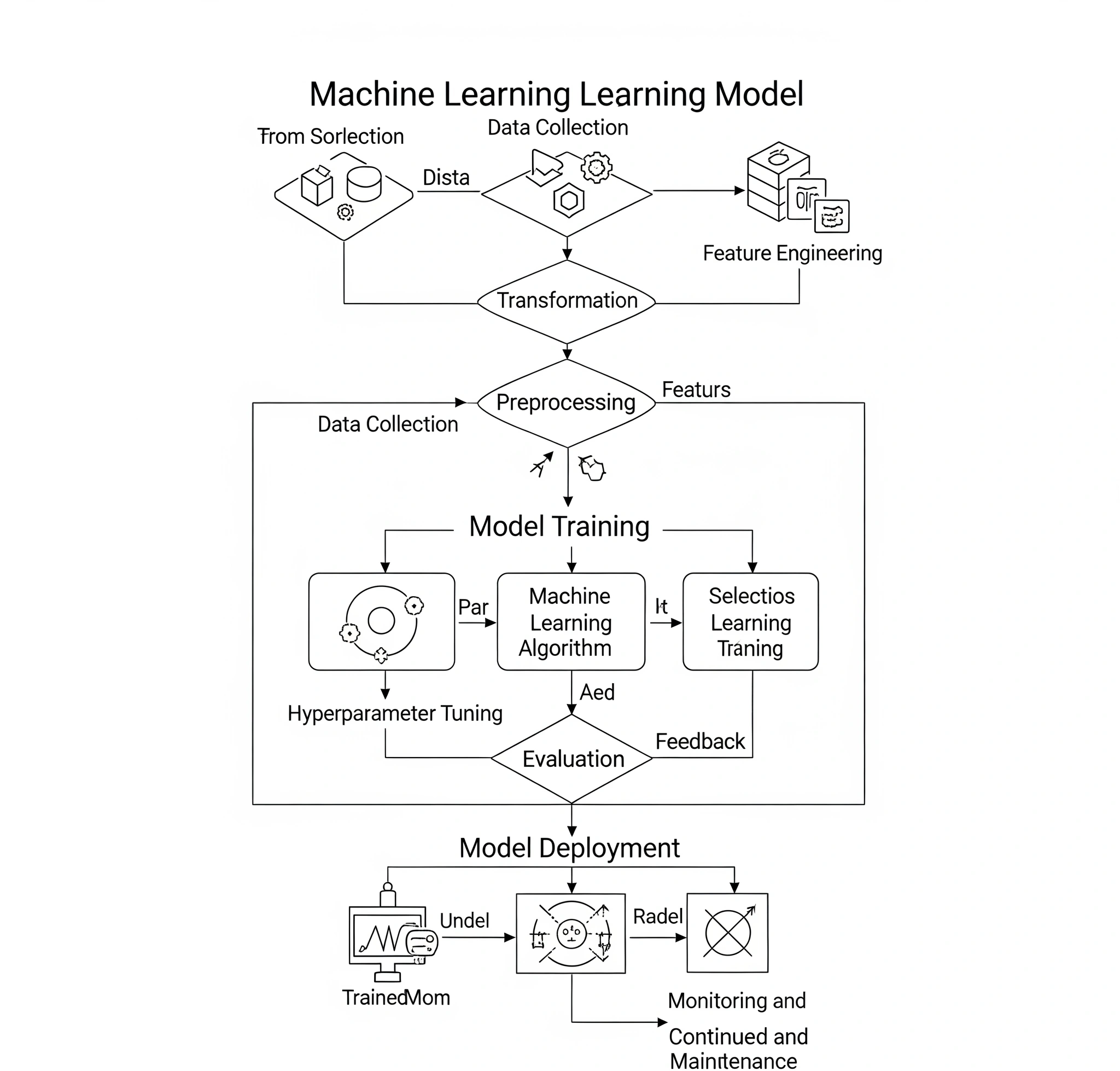
- Data Collection & Preprocessing: This is where raw data, often vast and messy, is gathered and cleaned. This phase is crucial because any existing biases in the data will be directly inherited by the AI model. For instance, if a dataset used to train a facial recognition system predominantly features individuals from one demographic, it may perform poorly or inaccurately when identifying individuals from underrepresented groups.
- Feature Engineering: Relevant features (attributes) are extracted from the raw data that the algorithm can learn from. The choice of features can inadvertently introduce or amplify biases.
- Model Training: The algorithm “learns” from the processed data, adjusting its internal parameters to minimize errors and make accurate predictions. This is where the statistical relationships and patterns within the data are encoded into the model.
- Model Evaluation: The trained model is tested on unseen data to assess its performance. Metrics like accuracy, precision, and recall are used, but these alone often fail to capture ethical considerations or fairness across different groups.
- Deployment: Once validated, the model is put into real-world use, making predictions or decisions.
- Monitoring & Feedback: Post-deployment, continuous monitoring is essential to detect performance degradation, drift, and emerging biases. Feedback loops allow for retraining and refinement.
The ‘Black Box’ Challenge
Ultimately, a key challenge lies in the fact that these algorithms, especially deep learning models, often act as “black boxes.” We can observe their inputs and outputs, but understanding the intricate decision-making process within can be incredibly complex. This inherent opacity makes identifying and mitigating biases a significant hurdle for developers and users alike.
—
Understanding the Implementation Ecosystem
Implementing AI in the real world is far more complex than just developing an algorithm. It involves a vast ecosystem of stakeholders, data pipelines, infrastructure, and human-in-the-loop processes. Consequently, each component introduces potential points of failure and opportunities for ethical compromises or the amplification of existing biases. Let’s consider the journey of an AI project from concept to deployment.
Data Scarcity and Quality Issues
Many organizations struggle to collect sufficient, high-quality, and representative data. Incomplete or skewed datasets directly translate into biased models. For example, a healthcare AI trained on data primarily from one hospital network might not perform optimally or fairly when deployed in a different region with a more diverse patient population or different diagnostic protocols. Therefore, the foundation of data must be robust.
Challenges with Legacy Systems and Integration
Integrating new AI solutions with existing, often siloed, legacy systems presents significant technical and organizational challenges. Data fragmentation can lead to inconsistent inputs and further exacerbate bias issues. Effectively, seamless integration is vital for consistent and fair AI performance.
The Importance of Diverse AI Teams
The teams building AI are often homogenous, lacking the diverse perspectives needed to anticipate and identify potential biases in data, model design, and application. This can lead to blind spots where unintended consequences are overlooked. Building a diverse team is not just about inclusion; it’s about better AI.
Navigating Regulatory Ambiguity
The regulatory landscape for AI ethics is still evolving. This ambiguity can leave organizations unsure about best practices, accountability, and compliance requirements, leading to a reactive rather than proactive approach to ethical AI. Clearer guidelines are certainly needed to foster responsible development.
Effective Human Oversight and Intervention
While AI promises automation, effective and ethical AI deployment still requires significant human oversight. Poorly defined human-in-the-loop processes or insufficient training for human operators can undermine the AI’s effectiveness and ethical safeguards. Humans remain indispensable in the AI ecosystem.
These challenges are not mere technical glitches; instead, they are systemic issues embedded within the operational realities of AI deployment. Without addressing them holistically, even the most well-intentioned AI initiatives can inadvertently perpetuate or even amplify societal inequalities.
—
A Project Simulation
Let me share a hypothetical, yet all too real, scenario that illustrates the insidious nature of algorithmic bias and the vital role of experience in navigating these challenges.
The Initial Promise at Apex Bank
Imagine a financial institution, let’s call it “Apex Bank,” embarking on an ambitious AI-driven credit scoring project. Their goal was clear: to leverage AI for faster, more accurate credit decisions, thereby increasing efficiency and reducing human error. As the lead digital architect on the consulting team, my role was to guide them through the implementation. Apex Bank possessed a massive historical dataset of loan applications, including applicant demographics, financial history, and past repayment behavior. Their existing, manual credit assessment process was slow and inconsistent, so the AI promised to be a genuine game-changer.
Unveiling the Discrepancy
We built a sophisticated deep learning model, training it on Apex Bank’s historical data. Initial performance metrics were stellar: high accuracy in predicting loan defaults. Naturally, the bank was thrilled. However, a nagging feeling prompted us to delve deeper than just overall accuracy. We decided to slice the data by demographic groups – age, gender, and crucially, geographical location. What we found was alarming. While the overall accuracy remained high, the model consistently assigned lower credit scores and had a significantly higher rejection rate for applicants residing in specific lower-income zip codes. This occurred even when their individual financial profiles (income, debt-to-income ratio) were comparable to approved applicants from wealthier areas.
Decoding the Root Cause: Historical Bias
After extensive investigation, we uncovered the root cause: historical bias embedded in the training data. For decades, Apex Bank had subtly, perhaps even unconsciously, practiced a form of redlining, approving fewer loans in certain neighborhoods due to perceived higher risk, regardless of individual applicant merit. Consequently, the AI, acting as a sophisticated pattern recognition engine, had simply learned and amplified this historical human bias. It didn’t “know” it was being discriminatory; instead, it was merely optimizing for the patterns it observed in the past.
The model had picked up on proxies for socio-economic status (like zip code) and used them as strong indicators for risk, effectively penalizing an entire group of individuals based on historical lending practices, not their current creditworthiness. The problem wasn’t in the algorithm itself, but fundamentally in the **data that fed it and the historical context from which that data emerged.**
This experience was a powerful reminder that AI is a mirror. It reflects our data, our biases, and our societal structures, sometimes with unsettling clarity. Without proactive measures and a deep understanding of the data’s provenance, even the most advanced AI can perpetuate injustice.
—
Original Insight
The Apex Bank case, and countless others like it, crystalize a crucial insight often overlooked in the hype surrounding AI: the most dangerous biases in AI are not bugs in the code; they are reflections of deeply ingrained societal biases, inadvertently encoded into algorithms through historical data.
Beyond Technical Glitches: The Societal Connection
Most discussions about AI bias focus on technical solutions: debiasing algorithms, explainable AI (XAI), and robust fairness metrics. While these are undoubtedly important, they often miss the “why.” The “why” is that AI, at its current stage, is fundamentally a pattern recognition system. If the patterns in the data reflect historical injustices, discriminatory practices, or systemic inequalities, the AI will learn those patterns and replicate them, often at scale and with chilling efficiency.
My original insight, forged in the trenches of real-world AI deployments, is this:
The primary battleground for AI ethics isn’t just in the mathematical equations or the lines of code; it’s in the often-unseen layers of data provenance, historical context, and human decision-making processes that precede and influence the AI’s “learning.”
Think of it as the “garbage in, garbage out” principle, but amplified and made insidious by the scale and complexity of AI. If the “garbage” is not literal junk, but rather subtly biased historical human decisions, then the AI will simply refine and automate that bias. Therefore, this is an “open code” moment because it forces us to look beyond the technical and into the socio-technical ecosystem where AI operates.
Prerequisites for Ethical AI
This perspective means that addressing AI bias effectively requires several key considerations:
- Archaeological Data Digs: Understanding the history and potential biases of the data sources. Where did the data come from? Who collected it? What human decisions are encoded within it?
- Sociological AI Teams: Building diverse teams that can identify and challenge assumptions and potential biases from different cultural, social, and economic perspectives.
- Ethical Design from Inception: Integrating ethical considerations at every stage of the AI lifecycle, not as an afterthought or a compliance checklist item.
- Accountability Beyond Algorithms: Recognizing that accountability for AI’s impact extends beyond the developers to the organizations deploying and profiting from these systems.
This perspective shifts the focus from merely fixing algorithmic “errors” to fundamentally questioning and reshaping the human processes and historical data that feed these powerful systems. It’s about recognizing that AI isn’t just technology; it’s a social construct, reflecting the world we build it in.
—
Solutive Counsel: An Adaptive Action Framework
Given the intricate nature of AI ethics and bias, a purely technical fix is insufficient. What’s truly needed is a holistic, adaptive action framework that integrates ethical considerations across the entire AI lifecycle. I propose a three-pillar framework: “Audit, Adapt, and Account.”

1: Audit – Proactive Bias Detection & Data Due Diligence
Before a single line of code is written or an algorithm selected, a rigorous audit phase is crucial.
- Data Provenance & Bias Audits: Don’t just look at data quality; investigate data history.
- Question: Where did this data originate? What human decisions are implicitly or explicitly captured within it? Are there any historical practices that could have introduced systematic inequalities?
- Action: Employ fairness metrics beyond traditional accuracy. Measure bias across different demographic groups (e.g., disparate impact, equal opportunity). Use explainable AI (XAI) techniques to understand model decisions, even if they’re “black boxes.” Tools like LIME, SHAP, and Responsible AI Toolbox can provide insights into feature importance and decision paths.
- Diverse Data Sourcing & Augmentation: Actively seek to diversify your training data to ensure representativeness.
- Action: Supplement underrepresented groups in your datasets through data augmentation or synthetic data generation (carefully and ethically, ensuring it doesn’t introduce new biases). Partner with organizations that collect diverse datasets.
- Team Diversity Assessment: Review the diversity of your AI development and ethics teams.
- Action: Actively recruit individuals from diverse backgrounds and experiences. Foster an inclusive environment where ethical concerns can be raised without fear.
2: Adapt – Iterative Ethical Design & Mitigation
Building ethical AI is not a one-time task; instead, it’s an ongoing, iterative process of adaptation and refinement.
- Bias Mitigation Techniques: Integrate algorithmic techniques specifically designed to reduce bias.
- Action: Explore pre-processing techniques (e.g., re-weighting, sampling) to balance datasets, in-processing techniques (e.g., adversarial debiasing) that modify the learning algorithm itself, and post-processing techniques (e.g., threshold adjustment) that calibrate predictions to ensure fairness across groups.
- Human-in-the-Loop (HITL) Design: Design systems where human oversight and intervention are integral, especially for high-stakes decisions.
- Action: Define clear intervention points where humans review AI recommendations. Provide comprehensive training for human operators on how to identify and override biased outputs. Continuously learn from human interventions to improve the AI.
- Ethical AI Guidelines & Principles: Develop and enforce clear ethical guidelines specific to your organization and AI applications.
- Action: Translate abstract ethical principles (e.g., fairness, transparency, accountability) into actionable technical and operational requirements. Regularly review and update these guidelines as technology evolves.
3: Account – Transparent Governance & Continuous Oversight
Accountability is the bedrock of trustworthy AI. This pillar focuses on establishing robust governance structures and ensuring continuous monitoring.
- AI Ethics Committees/Boards: Establish dedicated cross-functional bodies responsible for AI ethics.
- Action: These committees, comprising ethicists, technologists, legal experts, and business leaders, should review AI projects, assess risks, and advise on ethical deployment.
- Transparency & Explainability Protocols: Implement clear protocols for communicating how AI systems work, their limitations, and potential biases to end-users and affected stakeholders.
- Action: Use plain language to explain AI decisions. Provide mechanisms for users to appeal or question AI-driven outcomes. Develop clear documentation for internal and external stakeholders.
- Continuous Monitoring & Auditing: AI models can “drift” over time as real-world data changes, potentially reintroducing or creating new biases.
- Action: Implement robust monitoring systems to track model performance, fairness metrics, and potential bias indicators in real-time. Conduct regular, independent audits of deployed AI systems. Establish clear processes for rapid intervention and retraining when biases are detected.
This framework is not a rigid set of rules but a flexible guide. Its strength lies in its iterative nature, emphasizing that building trustworthy AI is an ongoing commitment, not a destination.
—
A Vision for the Future & Author Bio
The question “Can we trust AI?” is not a simple yes or no. Instead, it’s a complex query that demands introspection, proactive effort, and a deep understanding of both technology and humanity. As we navigate this new digital frontier, our collective responsibility is not merely to build intelligent machines, but to build just and equitable ones. The future of AI hinges on our willingness to confront its ethical challenges head-on, transforming it from a mirror reflecting our biases into a tool that helps us forge a more fair and inclusive world. This is not just about compliance; it’s about building a sustainable and trustworthy AI ecosystem for generations to come. How will your organization contribute to this critical journey?
—